Spark's Real-Time Mode: The End of the Two-Engine Problem

Spark's Real-Time Mode: The End of the Two-Engine Problem
For years, data teams building streaming systems faced an uncomfortable architectural choice. If you needed high-throughput ETL - processing millions of events per hour into your lakehouse - Spark Structured Streaming was the answer. If you needed sub-second latency for fraud detection, personalization, or real-time feature computation, you had to bring in Apache Flink.
That meant two engines, two codebases, two deployment models, two sets of operational expertise. Teams running both Spark and Flink in production know the tax: duplicated business logic, divergent governance models, and an ever-growing gap between how features are computed at training time (Spark) versus inference time (Flink).
Spark 4.1, released in December 2025, changes this calculus. Real-Time Mode (RTM) in Structured Streaming delivers millisecond-level latency through a fundamentally rearchitected execution engine - without abandoning the Spark API. This post breaks down what changed under the hood, how RTM actually compares to micro-batch and Flink, and where you should (and shouldn't) reach for it.
Why Micro-Batch Was Never Going to Get You to Milliseconds
To understand what RTM solves, you need to understand the ceiling micro-batch mode hits - and why shrinking batch size isn't the answer.
Spark Structured Streaming's micro-batch model works by dividing incoming data into discrete epochs, applying transformations to each batch, writing state to durable storage, and emitting output. This design is brilliant for throughput: fixed overheads are amortized across many records, vectorized execution kicks in efficiently, and hardware utilization stays high. It's why micro-batch has powered some of the world's most demanding ETL workloads at scale.
The problem is what happens when you try to push latency down. Every micro-batch carries fixed overhead that doesn't scale away:
- Writing commit logs to object storage before and after each batch
- Uploading state checkpoints for stateful queries
- Batch planning: logical and physical planning, task serialization, scheduling
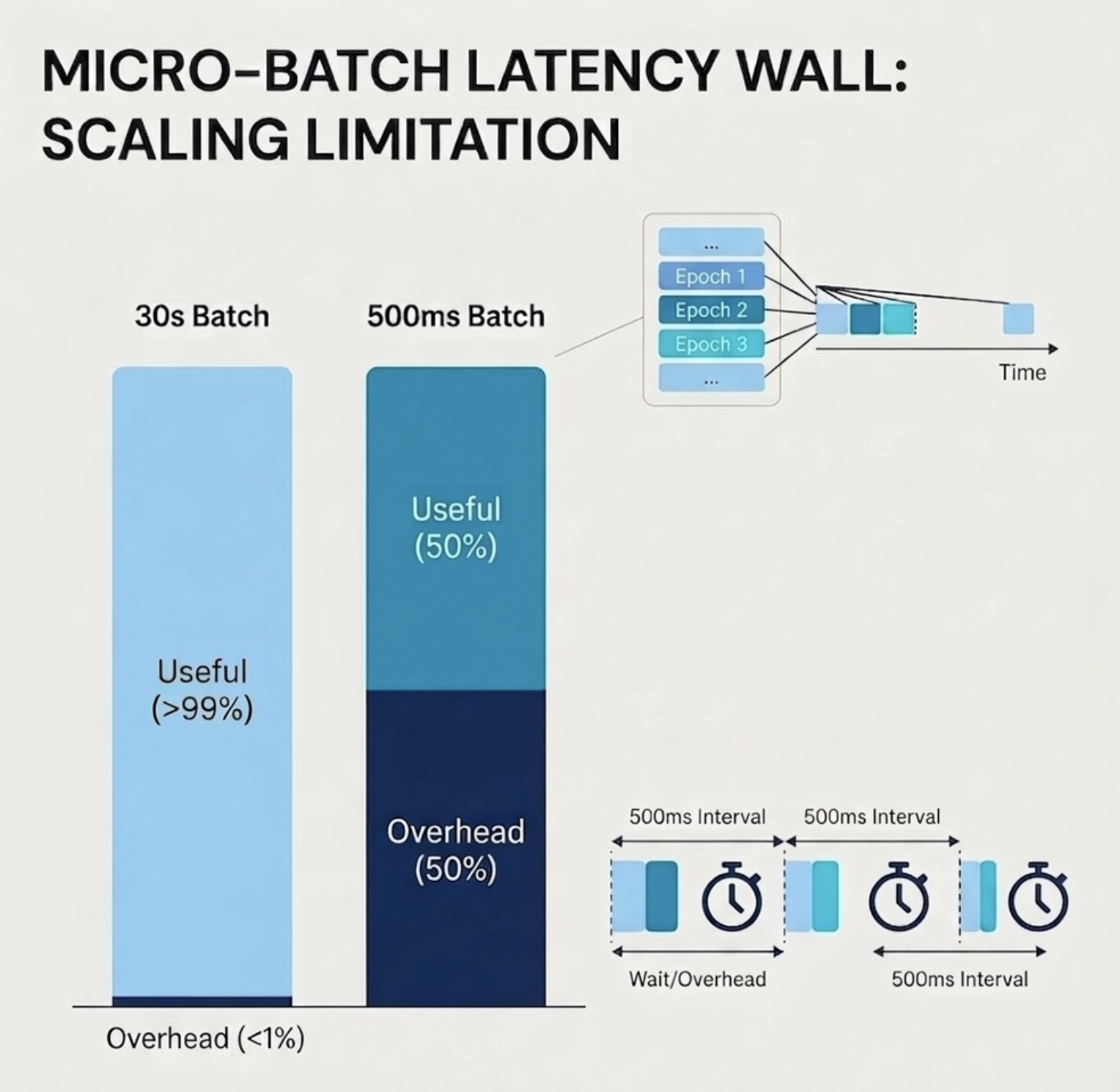
When your batch interval is 30 seconds, this overhead is invisible - a rounding error. When you try to push down to 500ms batches, those same fixed costs (which can themselves take hundreds of milliseconds) start to dominate. You hit a wall where making batches smaller actually increases end-to-end latency because the overhead outpaces the data volume.
This is the fundamental architectural ceiling of micro-batch. It isn't a tuning problem. It's a design constraint.
What Real-Time Mode Actually Changed
RTM doesn't patch micro-batch - it introduces a parallel execution model built on three architectural shifts:
1. Continuous Data Flow Inside Long Epochs
Rather than chopping the stream into small, frequent batches, RTM runs longer-duration epochs (the default is five minutes) but changes how data flows within those epochs. Instead of accumulating records and processing them together at the end, data moves through the pipeline continuously as it arrives - without waiting for a batch boundary.
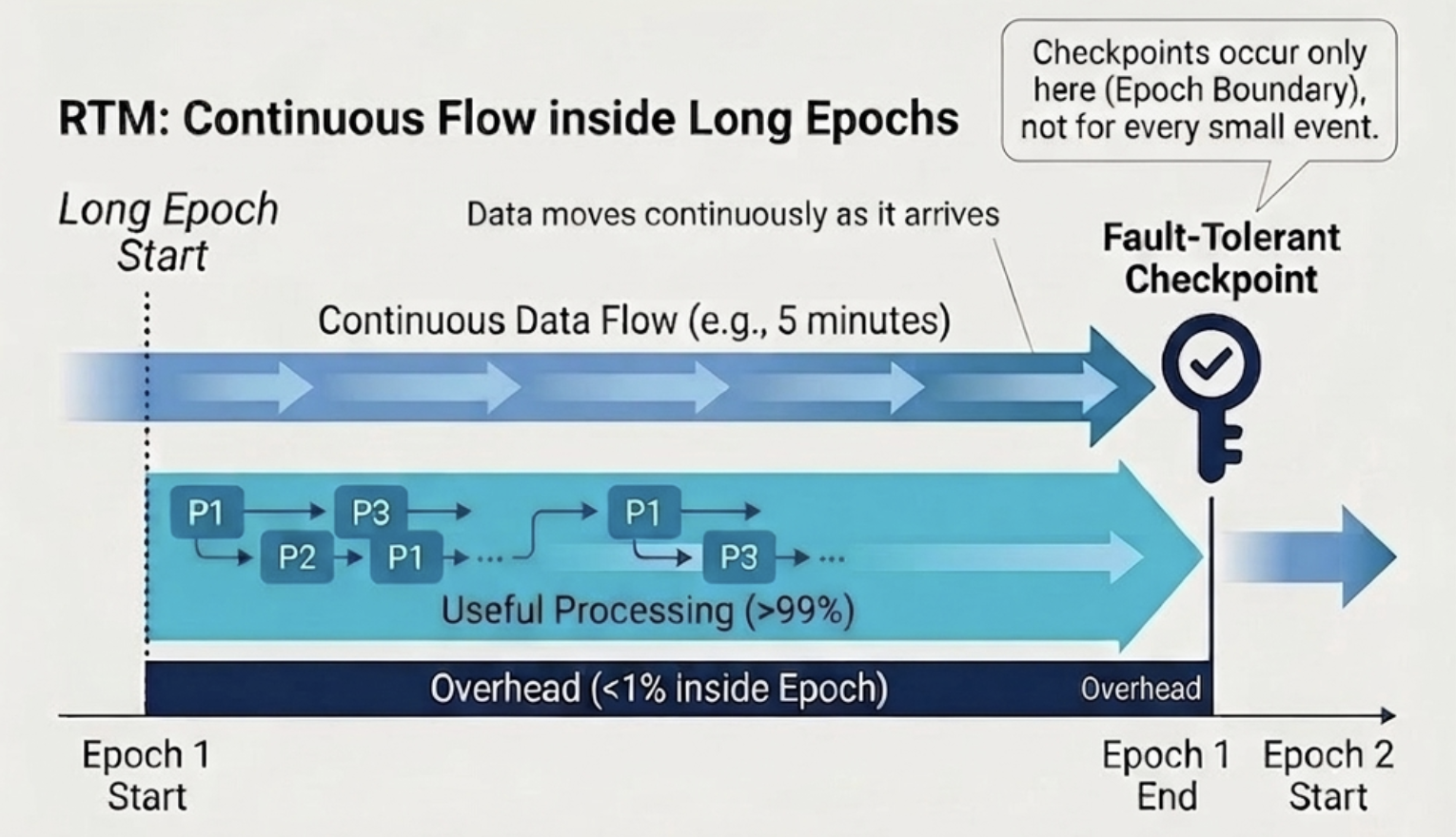
The checkpoint overhead moves to the epoch boundary, not to every mini-batch. You get the fault tolerance of checkpointing without paying for it on every event.
2. Concurrent Stage Scheduling
In micro-batch mode, pipeline stages execute sequentially. Stage 2 waits for Stage 1 to finish processing the full batch before it begins. For a pipeline with multiple stages, this sequential wait compounds into significant latency.
RTM schedules all stages simultaneously. Stage 2 begins processing rows as soon as Stage 1 produces them, without waiting for the full upstream batch to complete. The practical effect: multi-stage pipelines that used to accumulate seconds of scheduling wait now run in the time of the slowest single stage.
3. Streaming Shuffle (In-Memory, Non-Blocking)
Spark's traditional shuffle is designed for batch: buffer all records, pre-aggregate, write to disk, read from disk in the downstream stage. For real-time processing, this design is catastrophic - you can't emit results continuously if you're waiting to buffer everything first.
RTM replaces this with a streaming shuffle that passes data between stages as it's produced, in memory, without blocking on full-buffer completion. Key operators like aggregations are rearchitected to minimize buffering and emit partial results continuously rather than holding until the end.
Together, these three changes produce a qualitatively different execution model - one that can consistently hit p99 latencies below 300ms for a broad class of stateless and stateful workloads, and single-digit to sub-100ms latencies for simpler pipelines.
RTM vs. Micro-Batch: When to Use Which
RTM is not a replacement for micro-batch. It's a second mode optimized for a different point in the latency/throughput tradeoff space. Understanding where each mode lives is the key architectural decision.
| Dimension | Micro-Batch | Real-Time Mode |
|---|---|---|
| Target latency | Seconds to minutes | Milliseconds (sub-100ms to ~300ms p99) |
| Throughput | Very high (amortized overhead) | High, but overhead not fully amortized |
| Fault tolerance | Checkpoint per batch, fast recovery | Checkpoint per epoch, longer replay on failure |
| Operator maturity | Battle-tested, full feature set | Newer; some operators not yet supported |
| Code change to migrate | - | Single trigger swap: .trigger(RealTimeTrigger.apply()) |
| Best for | ETL, ingestion, hourly/daily analytics | Fraud detection, real-time ML features, personalization, alerting |
The migration story is genuinely simple: if you're already on Structured Streaming, switching to RTM is a one-line trigger change. No pipeline rewrites, no new API to learn. You can switch back just as easily if your workload doesn't benefit.
One nuance worth flagging: RTM's checkpointing behavior changes with epoch duration. Longer epochs mean less frequent checkpoints, which reduces overhead but means longer data replay on failure. Shorter epochs checkpoint more often but reintroduce some of the latency overhead you were trying to escape. For most operational workloads, the five-minute default epoch is a reasonable starting point - but test failure recovery behavior explicitly before going to production.
RTM vs. Apache Flink: An Honest Comparison

This is where the conversation gets interesting - and where you should read benchmarks with appropriate skepticism.
Databricks' own benchmarks show RTM outperforming Flink on feature engineering workloads by up to 92% in some scenarios. For that specific class of workload (stateless and stateful feature computation patterns), those results appear credible and have been corroborated by early production adopters. Coinbase, for instance, reported an 80%+ reduction in end-to-end latency after migrating real-time ML feature pipelines to RTM, hitting sub-100ms p99s at scale.
But "RTM beats Flink" is too broad a claim. The picture is more nuanced:
Where RTM is competitive or better
For feature engineering workloads - real-time aggregations, enrichments, joins against reference data - RTM's architecture maps well. The concurrent scheduler and streaming shuffle eliminate the bottlenecks that made Spark uncompetitive in these patterns. For teams already running Spark everywhere else, the operational simplicity of a single engine is itself a significant advantage.
Where Flink still holds advantages
True stream semantics. Flink's model is fundamentally event-driven: it processes one event at a time, continuously, without the concept of epochs or batches. RTM approximates this within epoch windows - close enough for most use cases, but not identical. For workloads that are extremely sensitive to per-event processing guarantees (not just latency SLAs), Flink's model is cleaner.
Watermarking and event-time handling. Flink's watermarking model is mature and expressive. RTM does not yet support event-time timers, which limits certain classes of stateful windowing operations. If your pipeline depends on late-data handling through event-time watermarks, Flink remains the safer choice today.
State management maturity. Flink's state backend options (RocksDB, heap) are well-understood in production at scale. RTM's stateful capabilities are built on transformWithState, which is powerful but newer. The operational experience for large stateful RTM workloads is still accumulating.
Delta Lake support. As of early 2026, RTM does not yet support Delta Lake as a sink. If your lakehouse architecture depends on writing to Delta tables with low latency, you're still on micro-batch for those pipelines.
The "logic drift" argument
One of the strongest practical arguments for RTM over Flink isn't performance - it's consistency. Teams running Spark for model training and Flink for inference routinely end up with divergent business logic: the feature computation in the training pipeline drifts from the production inference pipeline because they're maintained in two different codebases by people with different skills. RTM eliminates this. Training and serving use the same Spark code, the same transformations, the same team.
For data leads evaluating architecture: if your team is already deeply invested in Spark, the "single engine" argument for RTM is compelling even if Flink is technically faster for your specific workload. Managing two systems is expensive in ways that don't always show up in benchmarks.
A Note on Robustness
RTM is new. Spark 4.1 shipped in December 2025; GA on Databricks came shortly after. Before committing production workloads, there are a few robustness considerations worth taking seriously.
Operator coverage is still expanding. Not all Structured Streaming operators behave identically in RTM. Event-time timers aren't supported. transformWithState behaves differently - in RTM it processes one row at a time per key rather than all rows for a key per batch, which can change the semantics of stateful logic you wrote for micro-batch. Review your pipeline against the current compatibility matrix before migrating.
Failure recovery semantics differ. In micro-batch mode, a failed batch replays from the last checkpoint - typically a short window. In RTM, a failed epoch replays the full epoch window (up to five minutes by default). For workloads with idempotent sinks, this is fine. For workloads that aren't idempotent, this requires careful design.
Async checkpointing is a genuine improvement. One of the recent additions to RTM is asynchronous state checkpointing - state is now written to storage in parallel with data processing, removed from the critical latency path. This is architecturally correct and meaningfully reduces p99 latency for stateful workloads. It's also a signal that the team is thinking carefully about the right tradeoffs.
OSS Spark 4.1 support is limited. The open-source release of Spark 4.1 includes RTM for stateless transformations (projection, filtering, UDFs). Stateful RTM remains primarily a managed offering. If you're running self-managed Spark clusters, factor this into your planning.
The overall picture: RTM is not experimental, but it is still accumulating production mileage. For new workloads that fit the supported operator set, it's a reasonable production choice. For migrating complex stateful pipelines from micro-batch, move carefully - test failure scenarios explicitly and verify that your stateful logic behaves identically under the per-row semantics RTM uses.
Architectural Recommendation
If you're a data lead or architect deciding how to structure your streaming layer in 2026, here's how I'd think about it:
For new pipelines with latency requirements below one second: Start with RTM. Verify your operators are supported, test failure recovery, and leverage the single-API advantage.
For existing micro-batch pipelines that don't need sub-second latency: Stay on micro-batch. RTM is not better for high-throughput ETL - micro-batch's amortized overhead model is specifically designed for that workload. Don't fix what isn't broken.
For Flink workloads you're considering migrating: Evaluate per workload. Feature engineering and stateless enrichment pipelines are strong candidates. Complex stateful topologies with event-time watermarking are not ready for migration yet - check Flink's feature parity before committing.
For teams currently running both Spark and Flink: RTM gives you a concrete path to consolidating onto one engine. The savings in operational overhead, governance complexity, and logic drift are real. But treat it as a migration roadmap, not a switch to flip today.
The two-engine problem has defined how data teams architect streaming systems for nearly a decade. RTM doesn't fully eliminate it yet - Flink's feature set is still ahead in specific areas - but it closes the gap enough that the calculus has genuinely shifted. For most operational streaming workloads, Spark is now a credible answer where it simply wasn't before.
That's a meaningful change worth understanding before your next architecture review.
Tags
Keep up with us
Get the latest updates on data engineering and AI delivered to your inbox.
Contents in this story
Recommended for you

Code Smarter, Not Harder: Meet the New Notebook Code Generation on Dataverses
May 23, 2026 · 4 min read

Apache Iceberg 1.11.0 Release: Deletion Vectors, Variant Type, and V3 Maturity
May 22, 2026 · 7 min read

Spark Declarative Pipelines in Apache Spark 4.1: A Complete Guide
May 1, 2026 · 7 min read
